How to Upload a File to Confluence Using Api
Purpose
Using the Residue API can be helpful in automating certain operations within Confluence.
For instance, a Confluence user or administrator may need to upload an zipper to a page. Even so, going through the User Interface (UI) could be rather impractical depending on the number of target attachment files or target pages.
This document provides a step-past-footstep process on how to use the Confluence REST API to upload an attachment, provided y'all have the target page ID.
The suggested solution is provided as a set of bash commands using gyre and jq to run the Balance API call and manipulate json output.
You may use this instance to create an automation tool on your preferred coding language.
This document is provided as-is, what means that Atlassian Support won't provide assistance on modifying this example to fit your use case.
Withal, nosotros volition definitely support you if a REST API telephone call isn't working equally it should.
See Atlassian Back up Offerings for additional data.
Solution
The solution is broken downward into individual steps that we will then bring together together in a single crush script.
Define environment variables
These variables will be used along with the subsequent commands.
Some notes almost these variables:
- Brand sure the user performing these changes has the advisable Infinite Permissions and, if applicable, Page Restrictions. Note that Confluence Balance API follows the aforementioned permissions/restrictions when the user is performing like operations from the UI (browser).
- The zipper type should be either
imageorfile. This is used to determine the macro to preview the attachment that will be added to the folio. - The ID of the target page should be known. Meet How to get Confluence folio ID for how to get this value.
USER_NAME=<username> # the user must have the necessary permissions on the target page and space USER_PASSWORD=<user countersign> CONFLUENCE_BASE_URL=<Confluence Base URL> ATTACHMENT_TYPE=<image | file> ATTACHMENT_FILE_NAME=<full path to the zipper file> PAGE_ID=<target pageid> 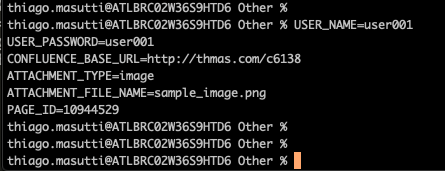
Upload zipper to the target folio
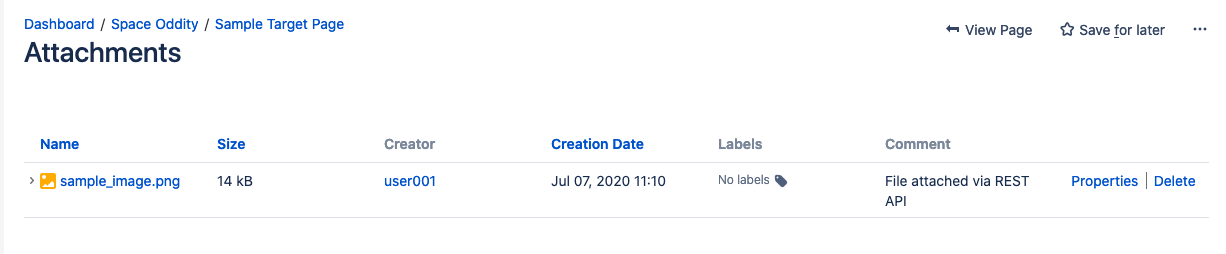
First, we will upload the zipper file to the target page. This is achieved by sending a Mail request to the /rest/api/content/<pageID>/child/attachment API method. The results of this API call are filtered to get the zipper title which should be name of the file. This indicates that the operation succeeded.
Please note that at this point, the attachment will not yet be added to the page content as this would be the equivalent of uploading the attachment using the UI equally shown below:

curl -u $USER_NAME:$USER_PASSWORD \ -10 POST \ -H "X-Atlassian-Token: nocheck" -F "file=@${ATTACHMENT_FILE_NAME}" -F "annotate=File fastened via REST API" \ ${CONFLUENCE_BASE_URL}/rest/api/content/${PAGE_ID}/child/attachment 2>/dev/cypher \ | jq -r '.results[].title' 
Become electric current content and metadata from the target page
In this pace, we'll get the page content and metadata (Title, Space, version, author, etc) and save them to a temporary surroundings variable. This data will then be used in the next steps. To do this, nosotros'll make a GET asking to the /remainder/api/content/<pageID>?expand=body.storage,version,space API method.
REST_CONTENT_FULL_OUTPUT=$(curl -u ${USER_NAME}:${USER_PASSWORD} \ ${CONFLUENCE_BASE_URL}'/rest/api/content/'${PAGE_ID}'?aggrandize=body.storage,version,infinite' two>/dev/zero) 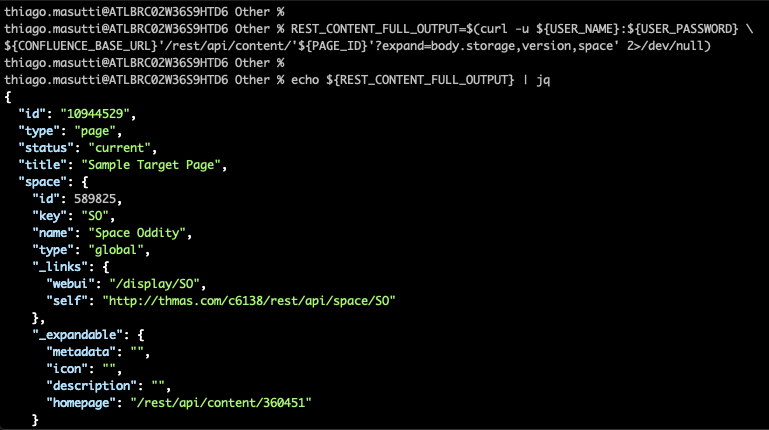
Edit the page content and metadata
Next, we'll filter the necessary information from the previous output and so that we can update the page content and its metadata.
Ii modifications are performed in this pace:
- Page version (
version.number): an increase of the folio version. - Page content (
body.storage.value): we'll include a macro to display the zipper at the bottom of the folio. Nosotros'll utilize the attachment type to determine which macro should be used.
At this point, we are just modifying the information without sending it to Confluence. The modifications are saved in a temporary file named modified-page-data.json.
if [ ${ATTACHMENT_TYPE} = "image" ]; then echo ${REST_CONTENT_FULL_OUTPUT} | \ jq '{body: {storage: {value: (.body.storage.value + "<p><ac:paradigm air conditioning:pinnacle=\"250\"><ri:attachment ri:filename=\"'${ATTACHMENT_FILE_NAME}'\" /></ac:image></p>"), representation: .torso.storage.representation}}, id: .id, type: .type, title: .championship, space: {key: .space.cardinal}, version: {number: (.version.number + one)}}' \ > modified-page-data.json else echo ${REST_CONTENT_FULL_OUTPUT} | \ jq '{body: {storage: {value: (.torso.storage.value + "<ac:structured-macro ac:name=\"view-file\" air conditioning:schema-version=\"1\" air-conditioning:macro-id=\"'${MACRO_UUID}'\"><air-conditioning:parameter ac:name=\"name\"><ri:attachment ri:filename=\"'${ATTACHMENT_FILE_NAME}'\" /></air conditioning:parameter><ac:parameter air conditioning:proper name=\"height\">250</ac:parameter></ac:structured-macro>"), representation: .torso.storage.representation}}, id: .id, type: .type, title: .title, space: {cardinal: .space.key}, version: {number: (.version.number + 1)}}' \ > modified-page-data.json fi 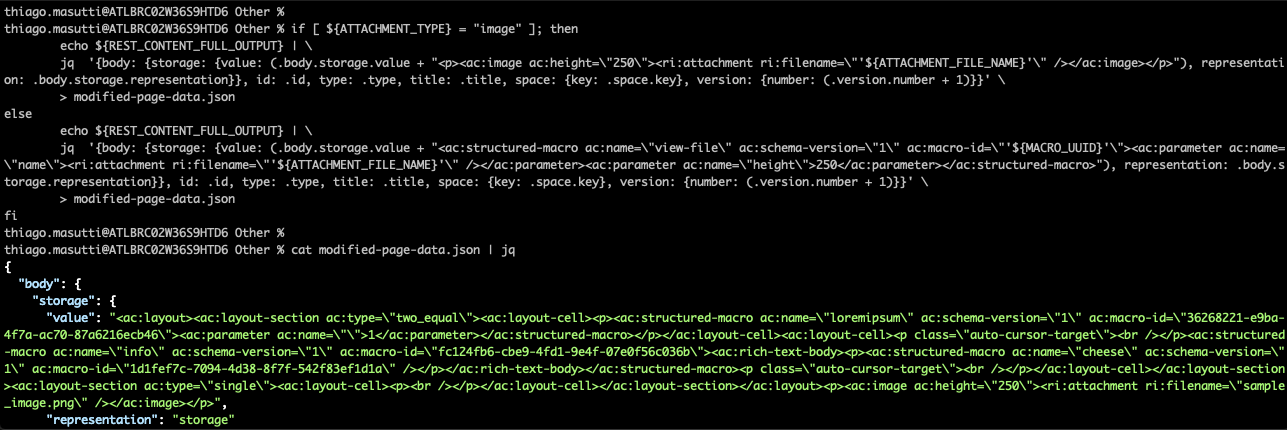
Upload the modified page
Now, nosotros'll read the temporary file with the modifications and update the target page by sending a PUT request to the /residuum/api/content/<pageID> API method.
At the cease of the execution, the pageID is filtered from the output and then that nosotros can confirm that it worked as expected.
scroll -u ${USER_NAME}:${USER_PASSWORD} \ -X PUT \ -H 'Content-Type: application/json' \ --data @modified-page-data.json \ ${CONFLUENCE_BASE_URL}'/rest/api/content/'${PAGE_ID} two>/dev/zilch \ | jq -r '.id' 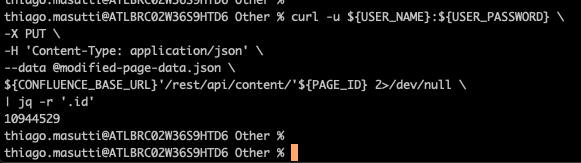
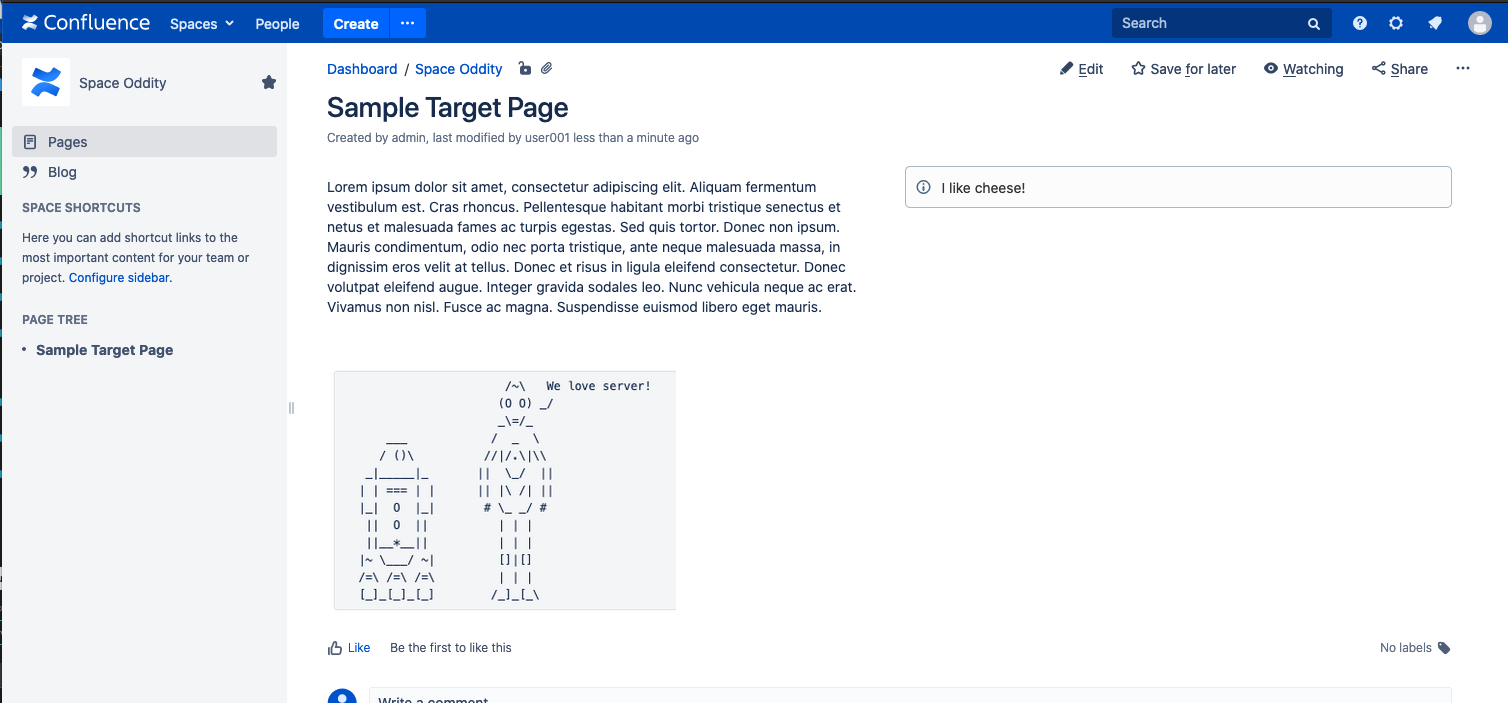
If we take a expect at the page after this has been performed, and then we'll see the image in the page content.
Combined Shell Script
The vanquish script beneath includes all of the steps highlighted to a higher place.
By creating a text file namedtarget_page_id.txt and loading information technology with a list of page IDs, you can bulk upload a specific attachment to multiple pages.
You lot may use this as an case to create an automation tool that fits your requirements and in your preferred coding linguistic communication.
USER_NAME=user001 USER_PASSWORD=user001 CONFLUENCE_BASE_URL=http://confluence.my.company.com/confluence ATTACHMENT_TYPE=image ATTACHMENT_FILE_NAME=new_sample_image.png for PAGE_ID in $(cat target_page_id.txt); do ####### # upload attachment to the target folio and capture the attachment title/name ####### ATTACHMENT_TITLE=$(curl -u $USER_NAME:$USER_PASSWORD \ -X Mail service \ -H "X-Atlassian-Token: nocheck" -F "file=@${ATTACHMENT_FILE_NAME}" -F "comment=File attached via Rest API" \ ${CONFLUENCE_BASE_URL}/rest/api/content/${PAGE_ID}/child/attachment 2>/dev/nada \ | jq -r '.results[].championship') if [ ${ATTACHMENT_TITLE} = ${ATTACHMENT_FILE_NAME} ]; then echo "File ${ATTACHMENT_TITLE} uploaded to page ${PAGE_ID}" repeat >modified-page-data.json MACRO_UUID=$(uuidgen 2>/dev/null) ####### # get the page content and metadata ####### REST_CONTENT_FULL_OUTPUT=$(whorl -u ${USER_NAME}:${USER_PASSWORD} \ ${CONFLUENCE_BASE_URL}'/rest/api/content/'${PAGE_ID}'?expand=body.storage,version,space' 2>/dev/null) ####### # get the page content and metadata; add 1 to the version number; add together the attachment to the bottom of the page; save the output to a temporary file ####### if [ ${ATTACHMENT_TYPE} = "image" ]; then echo ${REST_CONTENT_FULL_OUTPUT} | \ jq '{trunk: {storage: {value: (.body.storage.value + "<p><ac:paradigm ac:height=\"250\"><ri:attachment ri:filename=\"'${ATTACHMENT_FILE_NAME}'\" /></ac:image></p>"), representation: .trunk.storage.representation}}, id: .id, type: .type, title: .title, space: {key: .space.key}, version: {number: (.version.number + i)}}' \ > modified-folio-data.json else repeat ${REST_CONTENT_FULL_OUTPUT} | \ jq '{body: {storage: {value: (.body.storage.value + "<air conditioning:structured-macro ac:name=\"view-file\" air-conditioning:schema-version=\"i\" air conditioning:macro-id=\"'${MACRO_UUID}'\"><ac:parameter ac:proper name=\"name\"><ri:attachment ri:filename=\"'${ATTACHMENT_FILE_NAME}'\" /></ac:parameter><ac:parameter ac:proper name=\"peak\">250</ac:parameter></ac:structured-macro>"), representation: .body.storage.representation}}, id: .id, type: .type, title: .championship, space: {fundamental: .space.cardinal}, version: {number: (.version.number + ane)}}' \ > modified-folio-information.json fi ####### # update the folio ####### MODIFIED_PAGE_ID=$(curl -u ${USER_NAME}:${USER_PASSWORD} \ -10 PUT \ -H 'Content-Blazon: awarding/json' \ --data @modified-page-data.json \ ${CONFLUENCE_BASE_URL}'/residue/api/content/'${PAGE_ID} ii>/dev/nada \ | jq -r '.id' ) if [ ${MODIFIED_PAGE_ID} -eq ${PAGE_ID} ]; then echo "Folio ${PAGE_ID} successfully updated." else echo "Failed to updated page ${PAGE_ID}." fi else repeat "Failed to upload file to page ${PAGE_ID}" fi done Encounter Also
Confluence Server Residual API
Confluence REST API Documentation
Source: https://confluence.atlassian.com/display/CONFKB/Using+the+Confluence+REST+API+to+upload+an+attachment+to+one+or+more+pages
0 Response to "How to Upload a File to Confluence Using Api"
Post a Comment